|
Wenzhe Cai | 蔡文哲 I am a researcher at the Shanghai AI Laboratory, working closely with Dr. Tai Wang and Dr. Jiangmiao Pang. My research interests focus on Embodied AI, especially on building intelligent robots that can comprehend diverse language instructions and exhibit adaptive navigation behaviors in the dynamic open world. I obtained my Ph.D degree from Southeast University advised by Prof. Changyin Sun. During my Ph.D period, I am fortunate to be a visiting student at Peking University, advised by Prof. Hao Dong. |

|
News
|
ResearchMy research interests include Embodied AI, Visual Navigation and Deep Reinforcement Learning. |
|
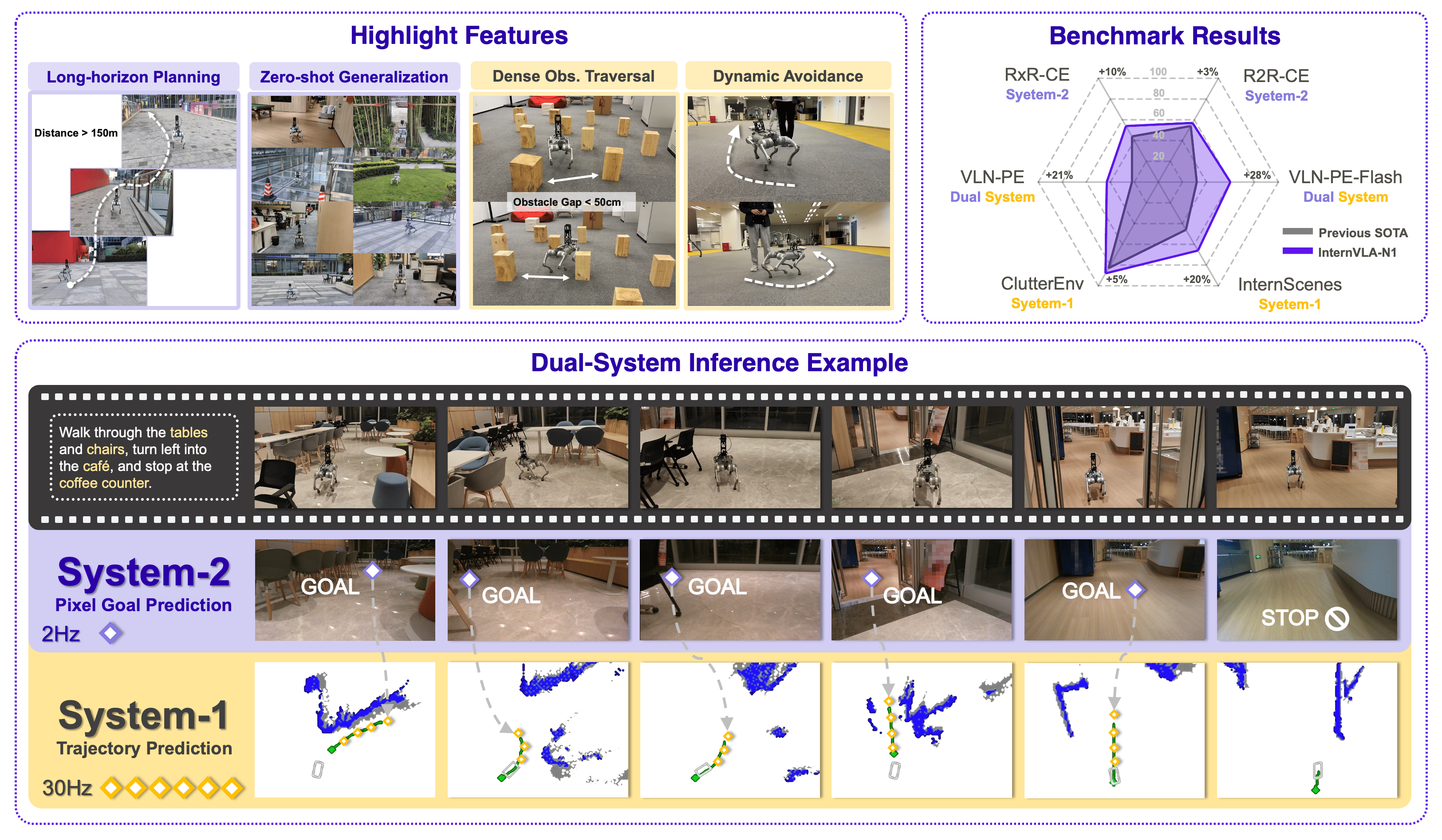
InternVLA-N1: An Open Dual-System Vision-Language Navigation Foundation Model with Learned Latent Plans
InternRobotics Team website / model / dataset / code We introduce InternVLA-N1, the first open dual-system vision-language navigation foundation model. |
|
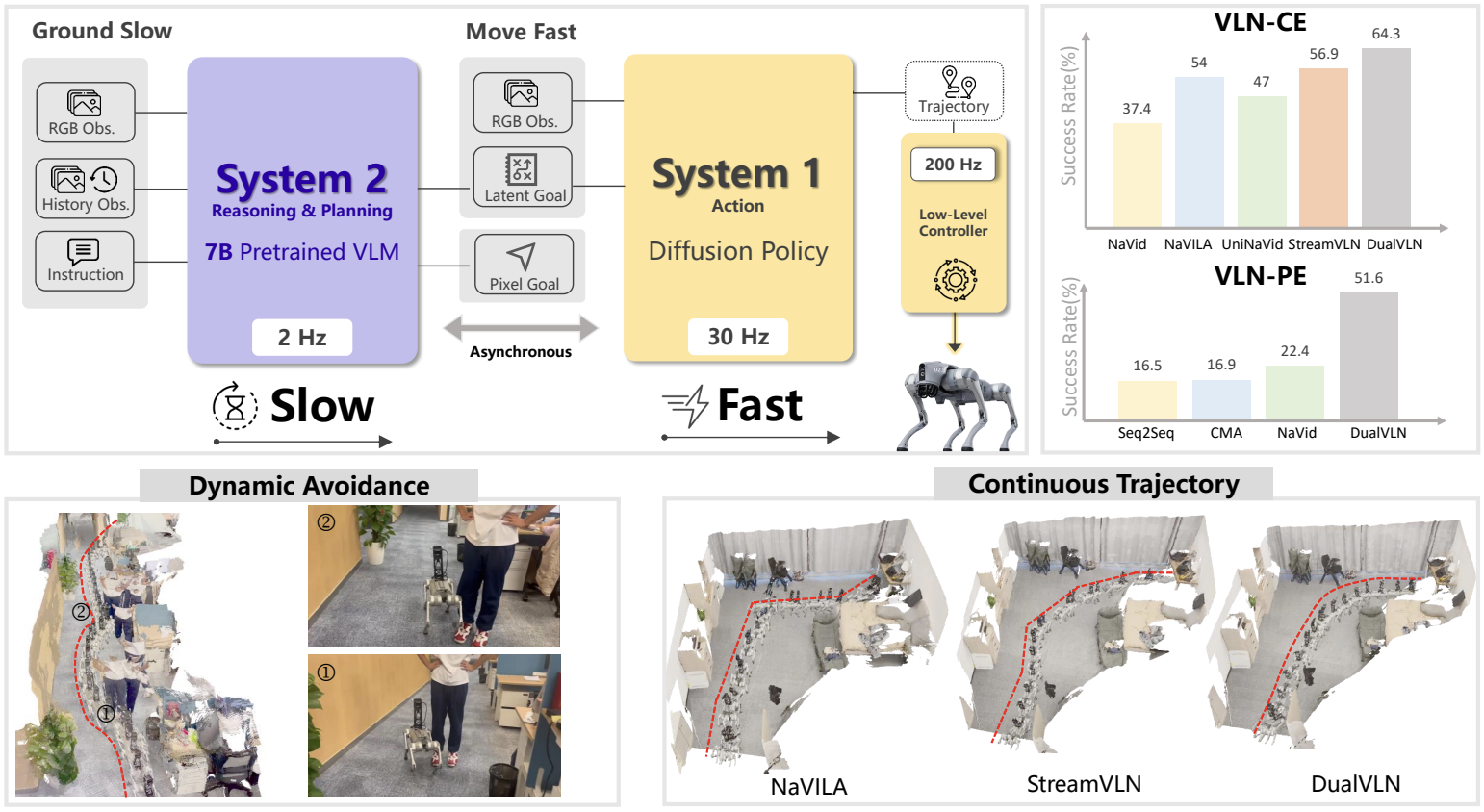
Ground Slow, Move Fast: A Dual-System Foundation Model for Generalizable Vision-Language Navigation
Meng Wei, Chenyang Wan, Jiaqi Peng, Xiqian Yu, Yuqiang Yang, Delin Feng, Wenzhe Cai, Chenming zhu, Tai Wang, Jiangmiao Pang, Xihui Liu International Conference on Learning Representations (ICLR), 2026 website / model / dataset / code A dual-system navigation foundation models that sets a new state-of-the-art on VLN-CE and VLN-PE tasks. |
|
InternScenes: A Large-scale Interactive Indoor Scene Dataset with Realistic Layouts
Weipeng Zhong*, Peizhou Cao*, Yichen Jin, Li Luo, Wenzhe Cai, Jingli Lin, Hanqing Wang, Zhaoyang Lyu, Tai Wang, Bo Dai, Xudong Xu, Jiangmiao Pang Conference on Neural Information Processing Systems (NeurIPS), 2025 website / arxiv / dataset / code We introduce InternScenes, a novel large-scale simulatable indoor scene dataset comprising approximately 40,000 diverse scenes by integrating three disparate scene sources, real-world scans, procedurally generated scenes, and designer-created scenes. |
|
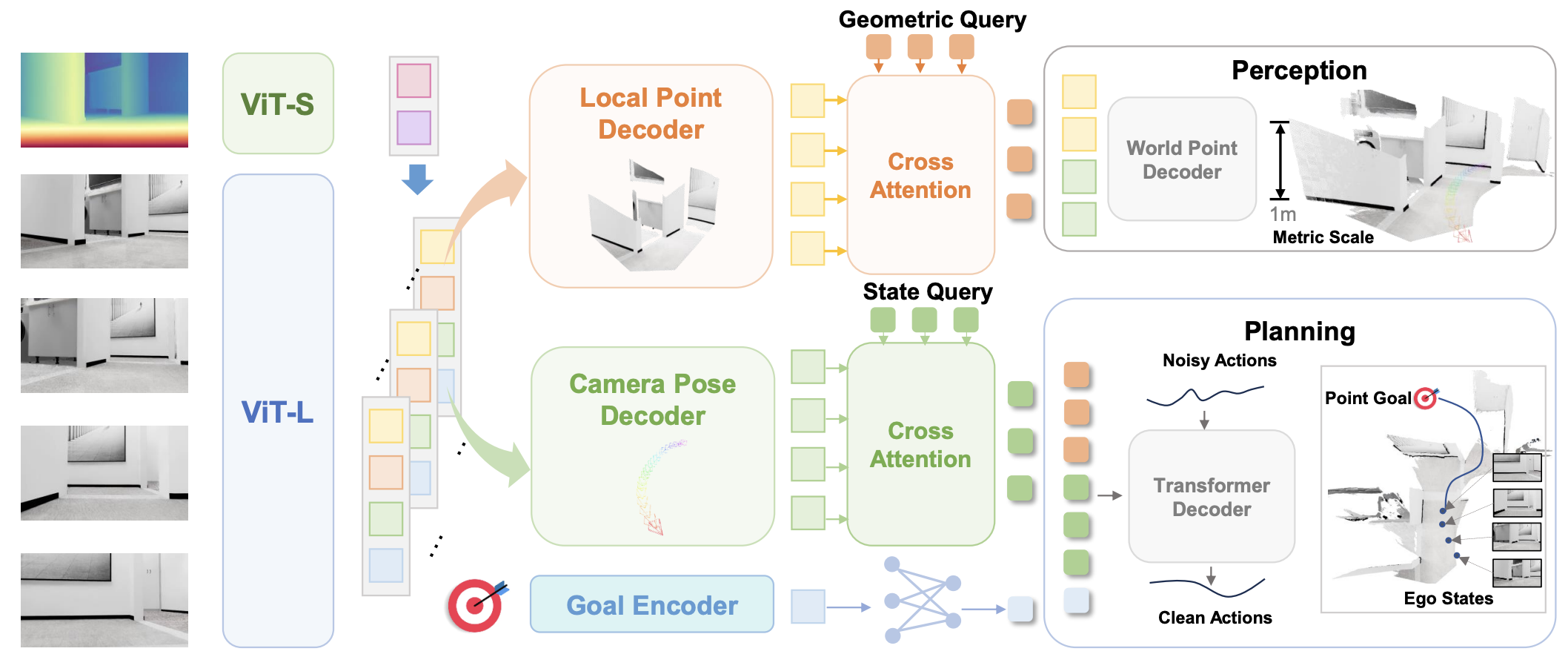
LoGoPlanner: Localization Grounded Navigation Policy with Metric-aware Visual Geometry
Jiaqi Peng*, Wenzhe Cai*, Yuqiang Yang*, Tai Wang, Yuan Shen, Jiangmiao Pang IEEE Conference on Robotics and Automation (ICRA), 2026 website / model / paper / code / X A localization-free end-to-end navigation policy that can make any robot into a zero-shot navigator within one camera. |
|
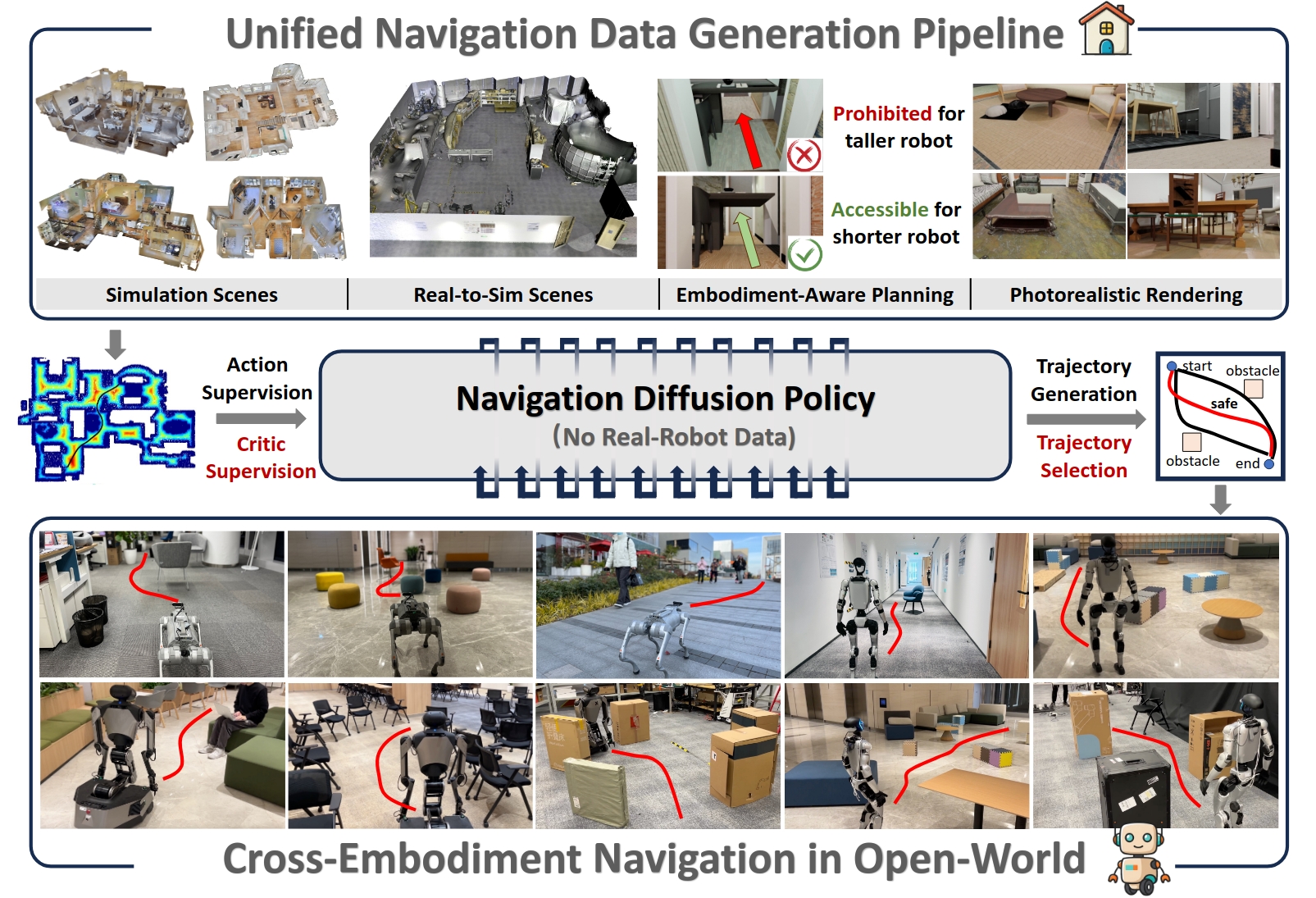
NavDP: Learning Sim-to-Real Navigation Diffusion Policy with Privileged Information Guidance
Wenzhe Cai*, Jiaqi Peng*, Yuqiang Yang, Yujian Zhang, Meng Wei, Hanqing Wang, Yilun Chen, Tai Wang, Jiangmiao Pang IEEE Conference on Robotics and Automation (ICRA), 2026 website / paper / video / github We present a sim-to-real navigation diffusion policy that can achieve cross-embodiment generalization in dynamic, cluttered and diverse real-world scenarios. |
|
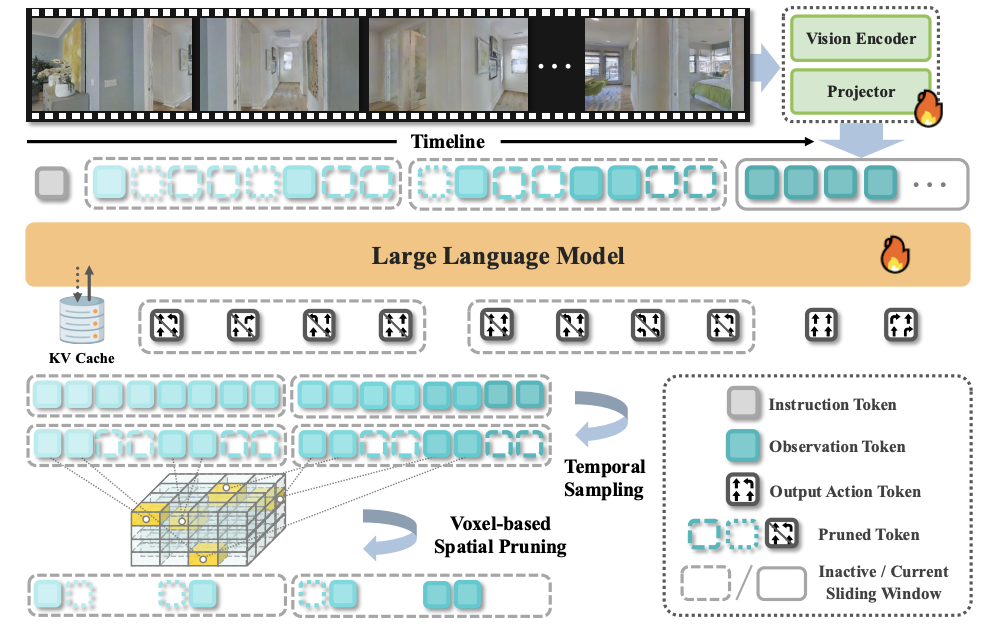
StreamVLN: Streaming Vision-and-Language Navigation via SlowFast Context Modeling
Meng Wei, Chenyang Wan, Xiqian Yu, Tai Wang, Yuqiang Yang, Xiaohan Mao, Chenming Zhu, Wenzhe Cai, Hanqing Wang, Yilun Chen, Xihui Liu, Jiangmiao Pang IEEE Conference on Robotics and Automation (ICRA), 2026 website / paper / video / github StreamVLN is a streaming VLN framework that employs a hybrid slow-fast context modeling strategy to support multi-modal reasoning over interleaved vision, language and action inputs. |
|
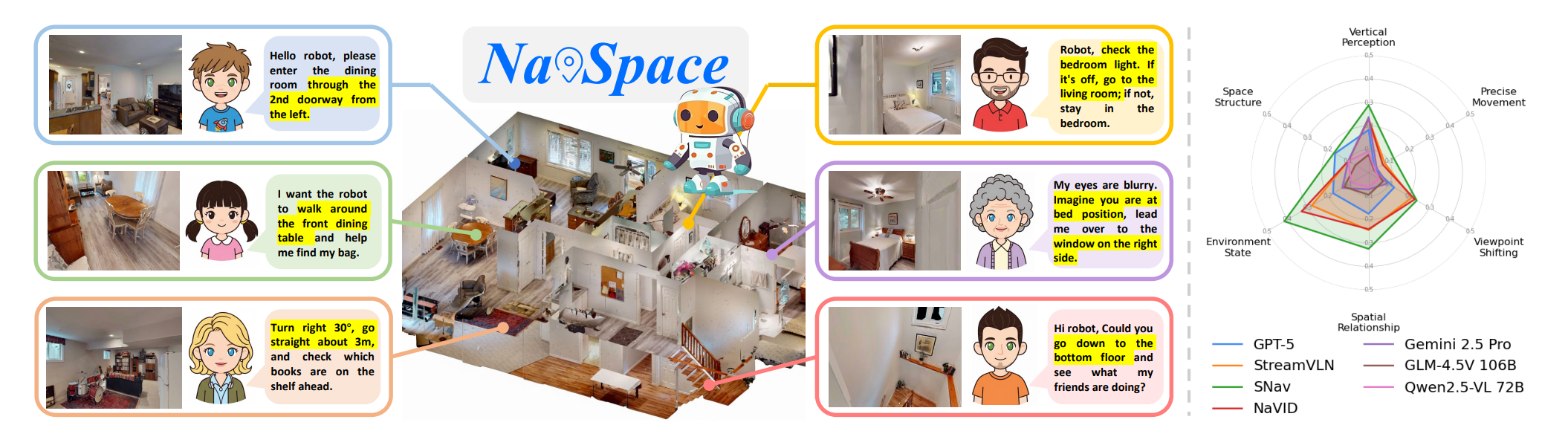
NavSpace: How Navigation Agents Follow Spatial Intelligence Instructions
Haolin Yang, Yuxing Long, Zhuoyuan Yu, Zihan Yang, Minghan Wang, Jiapeng Xu, Yihan Wang, Ziyan Yu, Wenzhe Cai, Lei Kang, Hao Dong IEEE Conference on Robotics and Automation (ICRA), 2026 website / paper / code We introduce the first spatial intelligence benchmark for instruction-based navigation, a more comprehensive benchmark to evaluate the cabalibities of navigation foundation models. |
|
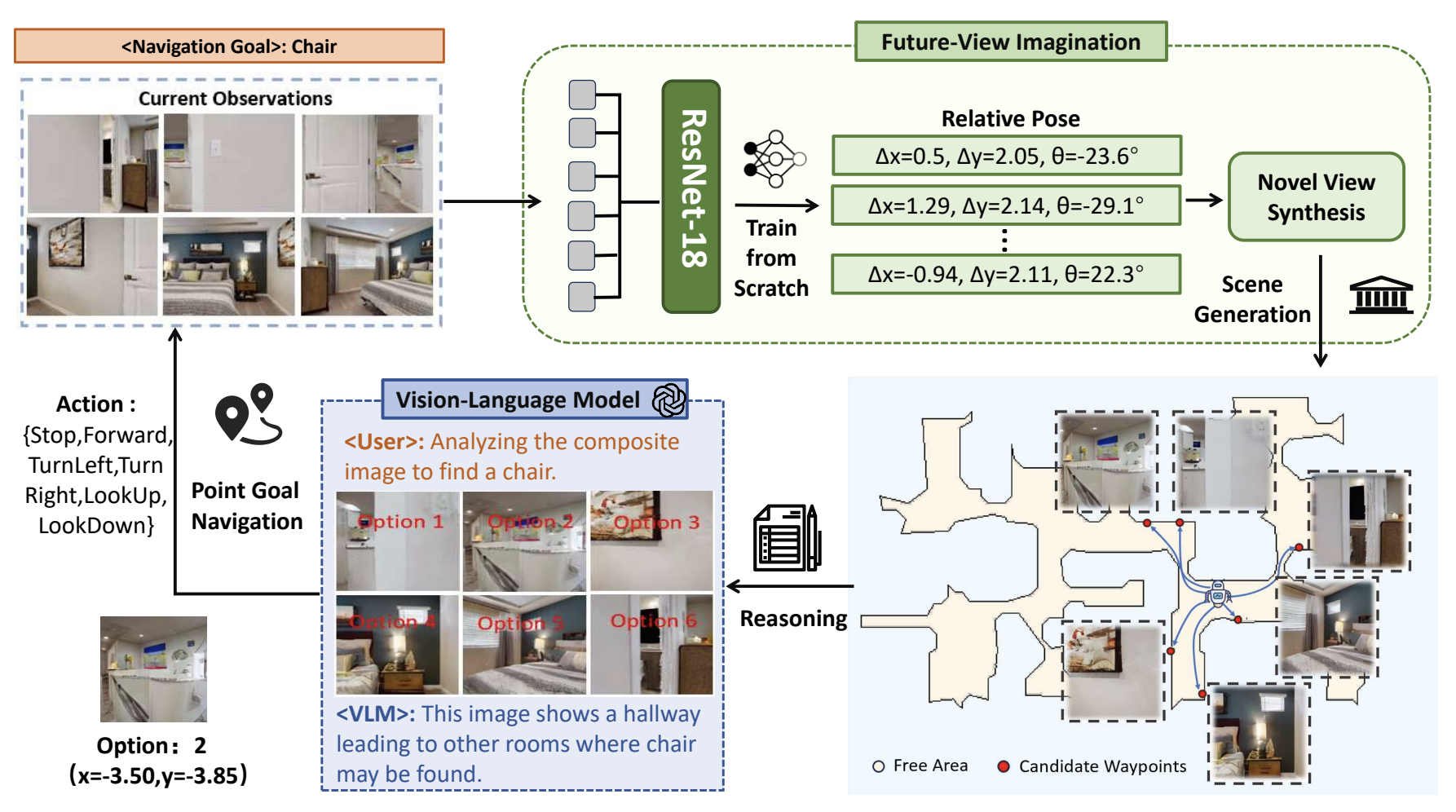
ImagineNav: Prompting Vision-Language Models as Embodied Navigator through Scene Imagination
Xinxin Zhao*, Wenzhe Cai*, Likun Tang, Teng Wang International Conference on Learning Representations (ICLR), 2025 website / paper / github We propose a novel navigation decision framework, which first use imagination to generate candidate future images and let the VLMs to select. This breaks ObjectGoal Navigation problem into a PointGoal navigation problem. |
|
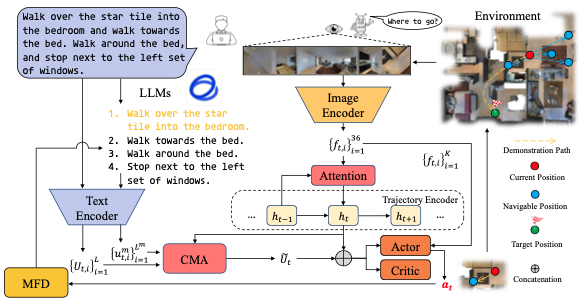
Boosting Efficient Reinforcement Learning for Vision-and-Language Navigation with Open-Sourced LLM
Jiawei Wang, Teng Wang, Wenzhe Cai, Lele Xu, Changyin Sun IEEE Robotics and Automation Letters (RA-L), 2024 paper / github We propose a hierarchical reinforcement learning method for vision-language navigation, which uses efficient open-sourced LLMs as a high-level planner and an RL-based policy for sub-instruction accomplishment. |

|
InstructNav: Zero-shot System for Generic Instruction Navigation in Unexplored Environment
Yuxing Long*, Wenzhe Cai*, Hongcheng Wang, Guanqi Zhan, Hao Dong Conference on Robot Learning (CoRL), 2024 website / paper / github We propose a zero-shot navigation system, InstructNav, which makes the first endeavor to handle multi-task navigation problems without any navigation training or pre-built maps. |
|
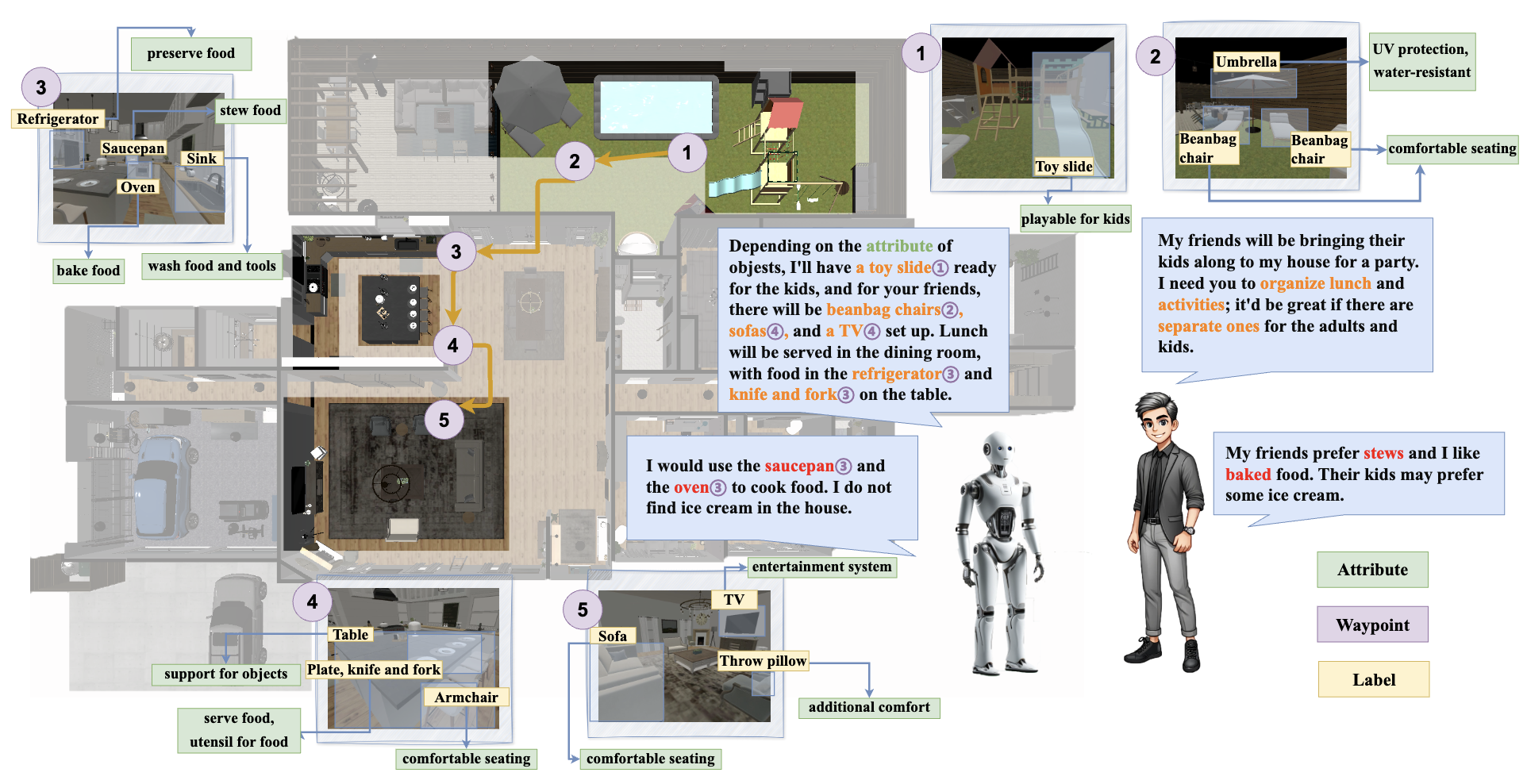
MO-DDN: A Coarse-to-Fine Attribute-based Exploration Agent for Multi-object Demand-driven Navigation
Hongcheng Wang, Peiqi Liu, Wenzhe Cai, Mingdong Wu, Zhengyu Qian, Hao Dong Conference on Neural Information Processing Systems (NeurIPS), 2024 website / paper / github We propose the Multi-Object Demand-Driven Navigation (MO-DDN) benchmark, which evaluates the agent navigation performance in multi-object exploration and aligns with personalized demands. |
|
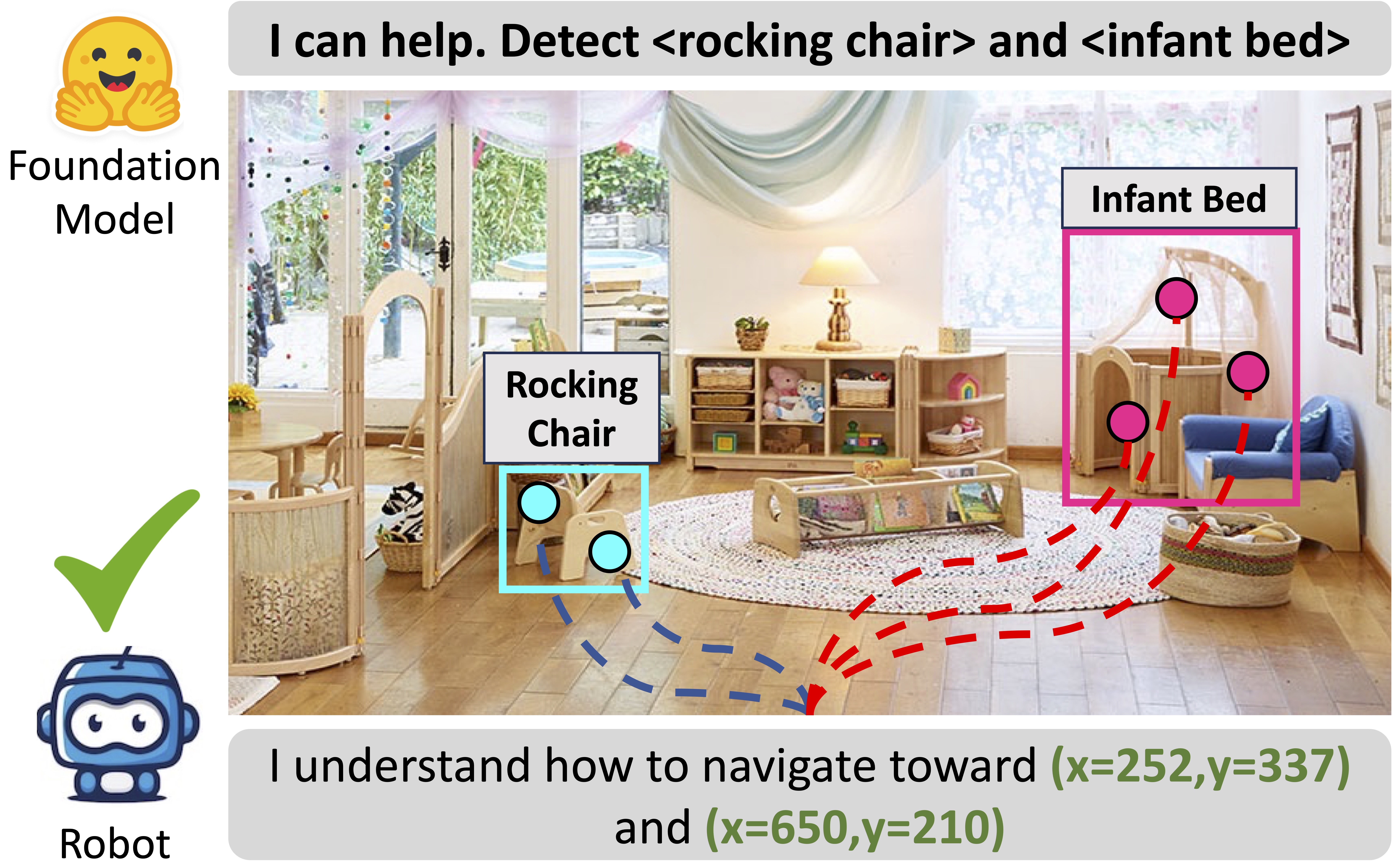
Bridging Zero-Shot Object Navigation and Foundation Models through Pixel-Guided Navigation Skill
Wenzhe Cai, Siyuan Huang, Guangran Cheng, Yuxing Long, Peng Gao, Changyin Sun, Hao Dong IEEE Conference on Robotics and Automation (ICRA), 2024 website / paper / github We propose a pure RGB-based navigation skill, PixNav, which takes in an assigned pixel as goal specification and can be used to navigate towards any objects. |
|
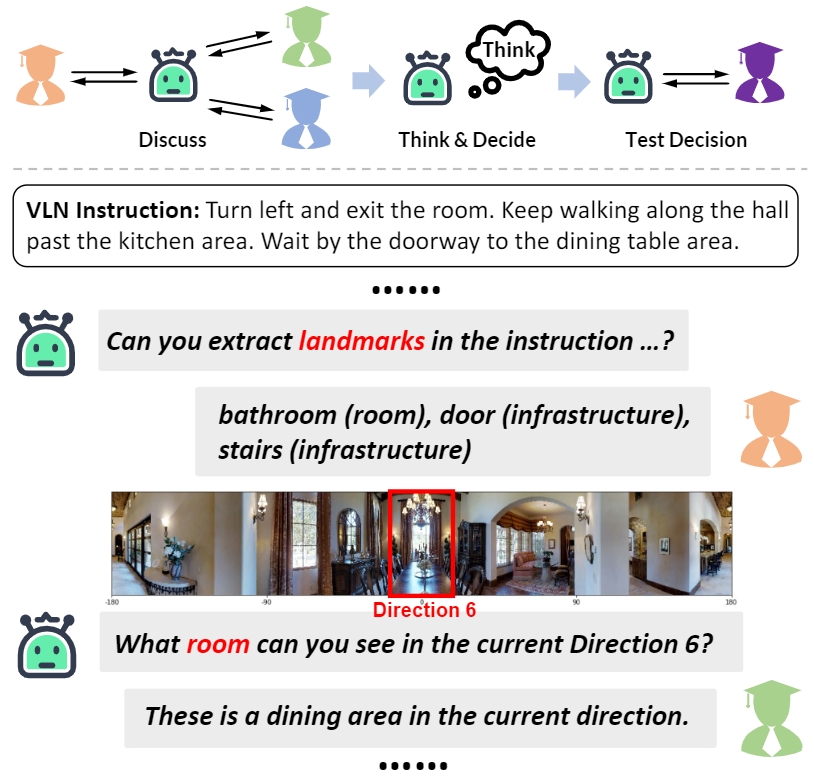
Discuss Before Moving: Visual Language Navigation via Multi-expert Discussions
Yuxing Long, Xiaoqi Li, Wenzhe Cai, Hao Dong IEEE Conference on Robotics and Automation (ICRA), 2024 website / paper / github DiscussNav agent actively discusses with multiple domain experts before moving. And with multi-expert discussion, our method achieves zero-shot visual language navigation without any training. |
|
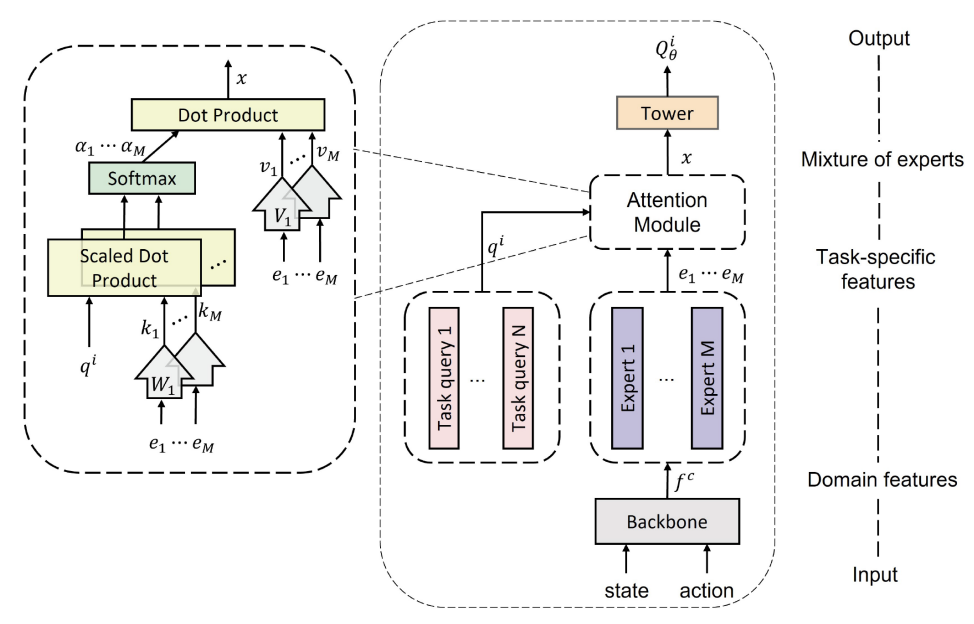
Multi-Task Reinforcement Learning With Attention-Based Mixture of Experts
Guangran Cheng, Lu Dong, Wenzhe Cai, Changyin Sun IEEE Robotics and Automation Letters (RA-L), 2023 paper / github We propose a soft mixture of experts (MoE) based reinforcement learning method to tackle multi-task robotics control problems, which effectively captured the latent relationships among different tasks. |

|
XuanCE: A Comprehensive and Unified Deep Reinforcement Learning Library
Wenzhang Liu, Wenzhe Cai, Kun Jiang, Guangran Cheng, Yuanda Wang, Jiawei Wang, Jingyu Cao, Lele Xu, Chaoxu Mu, Changyin Sun Journel of Machine Learning Research (JMLR), 2023 (under review) github / paper XuanCE is an open-source ensemble of Deep Reinforcement Learning (DRL) algorithm implementations, which supports both single-agent RL and multi-agents RL algorithms. |
|
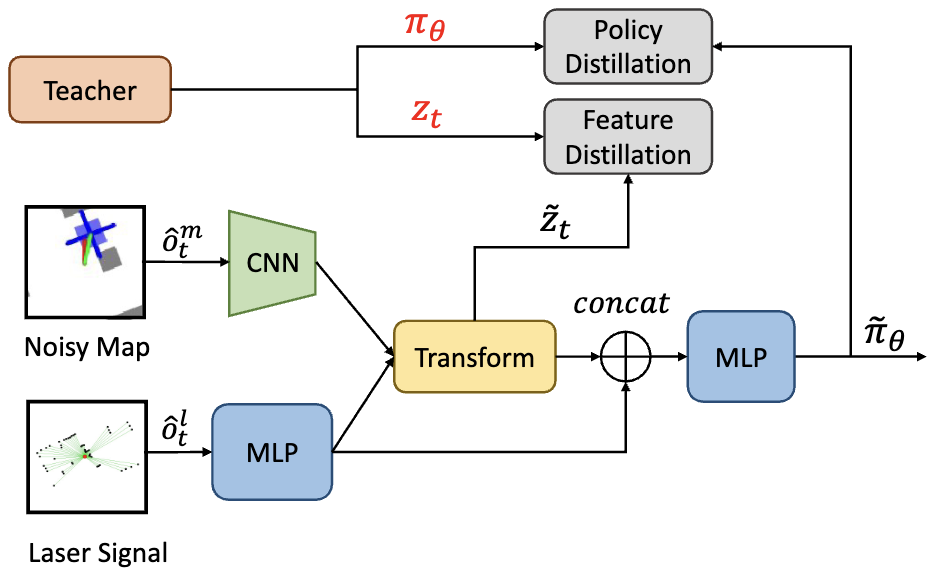
Robust Navigation with Cross-Modal Fusion and Knowledge Transfer
Wenzhe Cai*, Guangran Cheng*, Lingyue Kong, Lu Dong, Changyin Sun IEEE Conference on Robotics and Automation (ICRA), 2023 website / paper / github We propose a efficient distillation architecture to tackle the sim-to-real gap of an RL-based navigation policy. Our experiment shows our architecture outperforms the domain randomization techniques. |
|
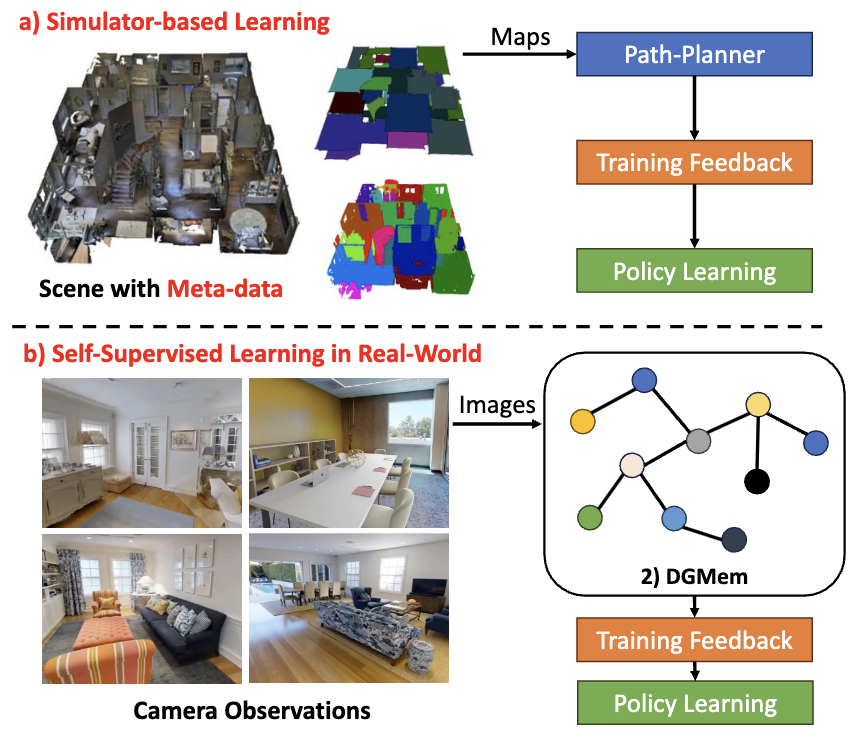
DGMem: Learning Visual Navigation Policy without Any Labels by Dynamic Graph Memory
Wenzhe Cai, Teng Wang, Guangran Cheng, Lele Xu, Changyin Sun Applied Intelligence, 2024 paper We discuss the self-supervised navigation problem and present Dynamic Graph Memory (DGMem), which facilitates training only with on-board observations. |

|
Learning a World Model with Multi-Timescale Memory Augmentation
Wenzhe Cai, Teng Wang, Jiawei Wang, Changyin Sun IEEE Transactions on Neural Networks and Learning Systems (TNNLS), 2022 paper We propose a novel action-conditioned video prediction method which introduces optical flow prediction to model the influence of actions and incorporate the optical-flow based image prediction to improve the long-term prediction quality. |
ServicesReviewer: RAL, TNNLS, TAI, ICRA, ICLR, ICCV, CoRL, IROS. |
Honers & Awards SEU Doctoral Entrance Scholarship |